Efficient AI applications
CAE-GReaT
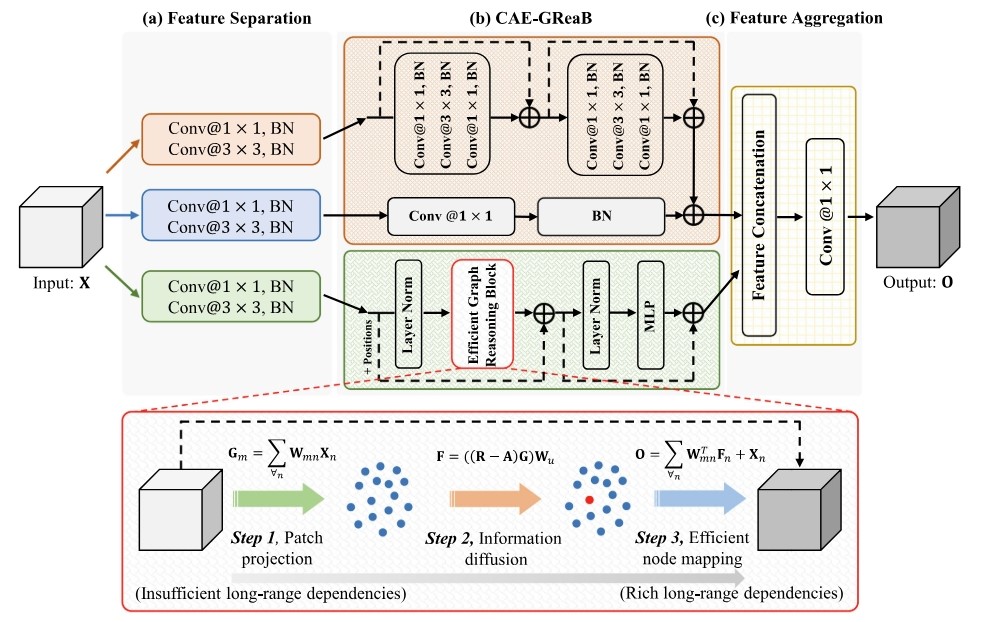
Convolutional Neural Networks (CNNs) and Vision Transformer (ViT) are two primary frameworks for current semantic image recognition tasks in the community of computer vision. The general consensus is that both CNNs and ViT have their latent strengths and weaknesses, e.g., CNNs are good at extracting local features but difficult to aggregate long-range feature dependencies, while ViT is good at aggregating long-range feature dependencies but poorly represents in local features. In this paper, we propose an auxiliary and integrated network architecture, named Convolutional-Auxiliary Efficient Graph Reasoning Transformer (CAE-GReaT), which joints strengths of both CNNs and ViT into a uniform framework. CAE-GReaT stands on the shoulders of the advanced graph reasoning transformer and employs an internal auxiliary convolutional branch to enrich the local feature representations. Besides, to reduce the computational costs in graph reasoning, we also propose an efficient information diffusion strategy. Compared to the existing ViT models, CAE-GReaT not only has the advantage of a purposeful interaction pattern (via the graph reasoning branch), but also can capture fine-grained heterogeneous feature representations (via the auxiliary convolutional branch).
CTO
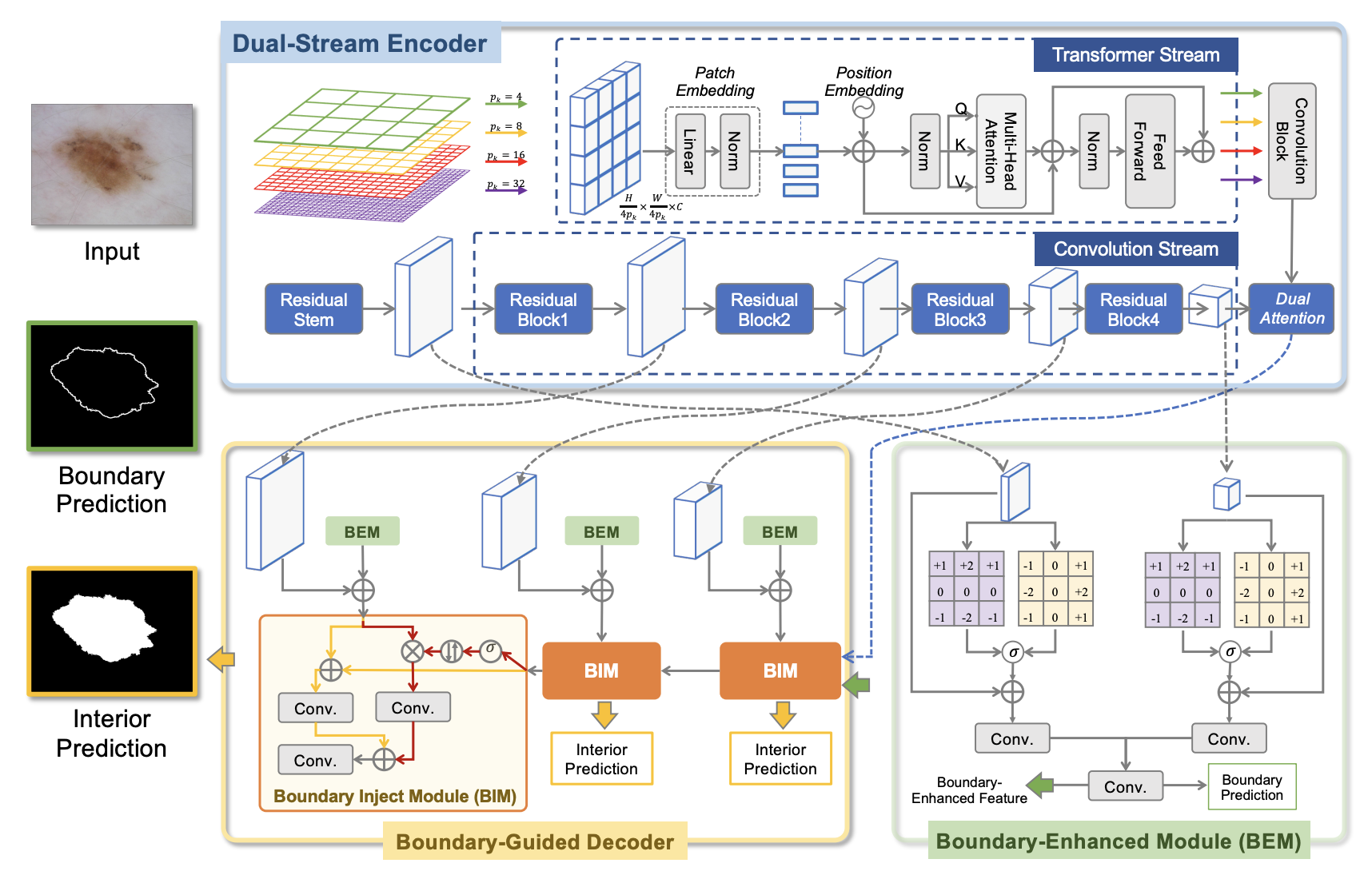
Medical image segmentation is a fundamental task in the community of medical image analysis. In this paper, a novel network architecture, referred to as Convolution, Transformer, and Operator (CTO), is proposed. CTO employs a combination of Convolutional Neural Networks (CNNs), Vision Transformer (ViT), and an explicit boundary detection operator to achieve high recognition accuracy while maintaining an optimal balance between accuracy and efficiency. The proposed CTO follows the standard encoder-decoder segmentation paradigm, where the encoder network incorporates a popular CNN backbone for capturing local semantic information, and a lightweight ViT assistant for integrating long-range dependencies. To enhance the learning capacity on boundary, a boundary-guided decoder network is proposed that uses a boundary mask obtained from a dedicated boundary detection operator as explicit supervision to guide the decoding learning process.
AUA
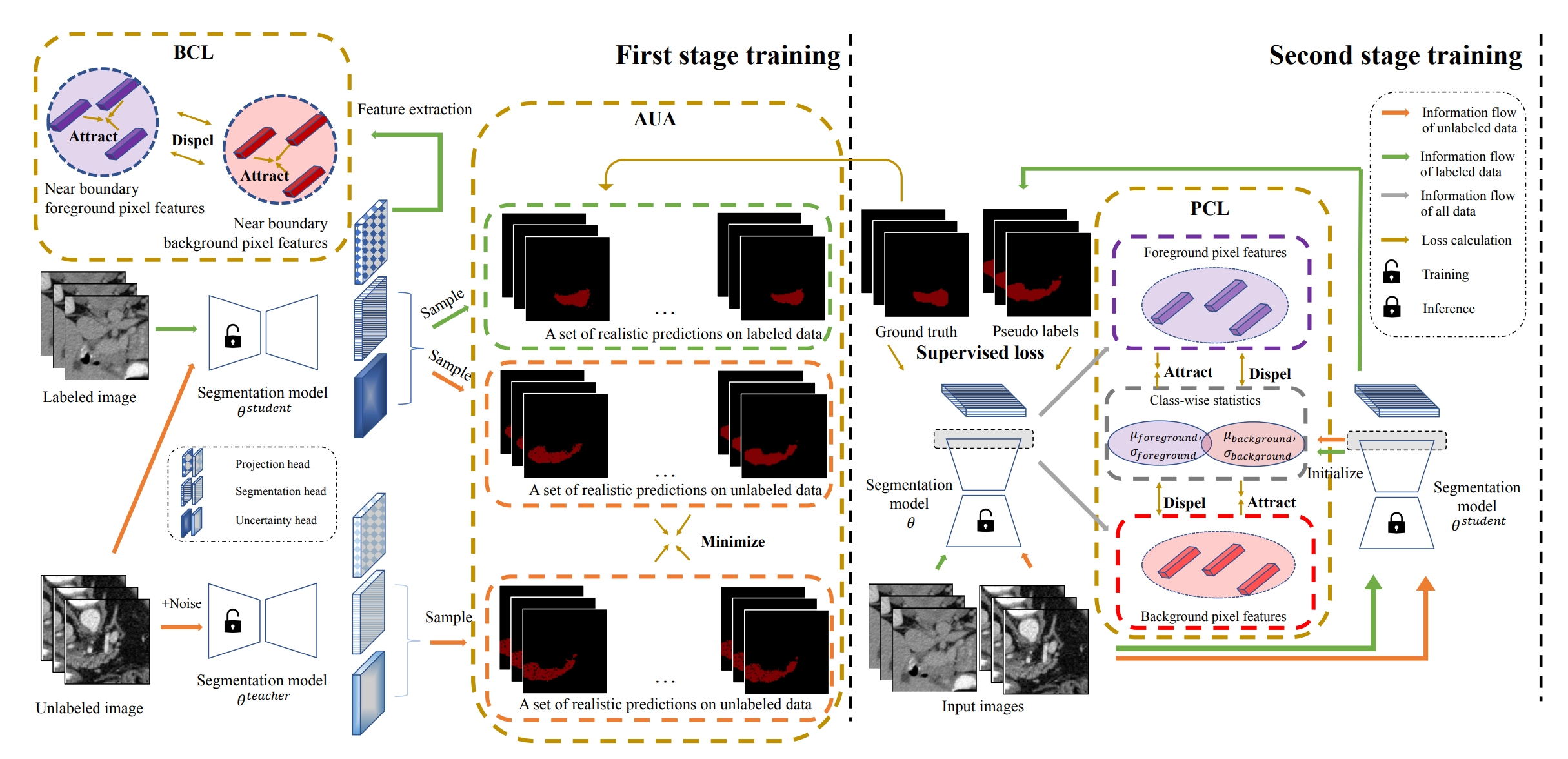
This paper presents a simple yet effective two-stage framework for semi-supervised medical image segmentation. Unlike prior state-of-the-art semi-supervised segmentation methods that predominantly rely on pseudo supervision directly on predictions, such as consistency regularization and pseudo labeling, our key insight is to explore the feature representation learning with labeled and unlabeled (i.e., pseudo labeled) images to regularize a more compact and better-separated feature space, which paves the way for low-density decision boundary learning and therefore enhances the segmentation performance. A stage-adaptive contrastive learning method is proposed, containing a boundary-aware contrastive loss that takes advantage of the labeled images in the first stage, as well as a prototype-aware contrastive loss to optimize both labeled and pseudo labeled images in the second stage. To obtain more accurate prototype estimation, which plays a critical role in prototype-aware contrastive learning, we present an aleatoric uncertainty-aware method, namely AUA, to generate higher-quality pseudo labels. AUA adaptively regularizes prediction consistency by taking advantage of image ambiguity, which, given its significance, is under-explored by existing works. Our method achieves the best results on three public medical image segmentation benchmarks.
Automated Vision-Based Wellness Analysis
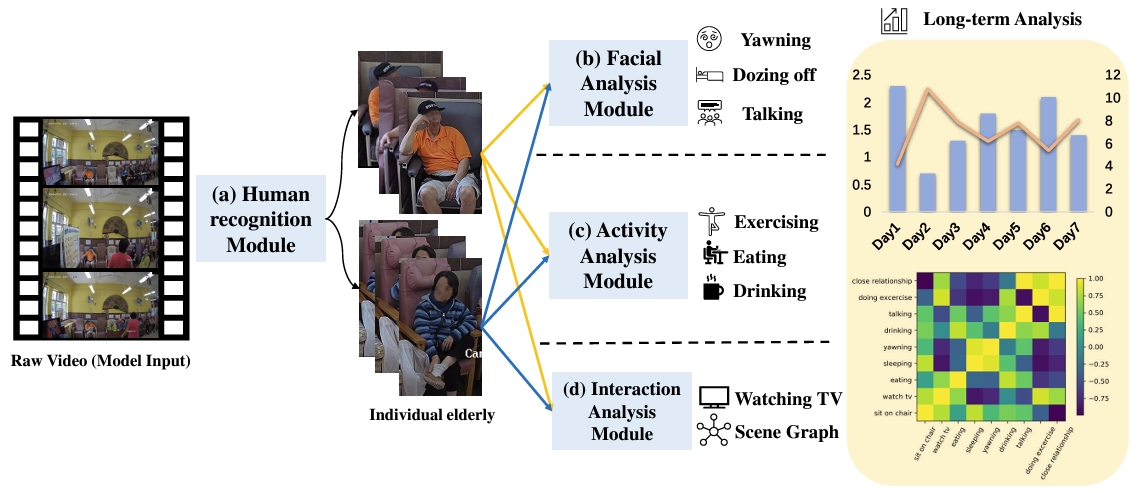
The growth in the aging population require caregivers to improve both efficiency and quality of healthcare. In this study, we develop an automatic, vision-based system for monitoring and analyzing the physical and mental well-being of senior citizens. Through collaboration with Haven of Hope Christian Service, we collect video recording data in the care center with surveillance camera. We then process and extract personalized facial, activity, and interaction features from the video data using deep neural networks. This integrated health information systems can assist caregivers to gain better insights into the seniors they are taking care of. We report findings of our analysis and evaluate the system quantitatively to demonstrate the effectiveness.
Reference
- Dong Zhang, Yi Lin, Jinhui Tang, Kwang-Ting Cheng. CAE-GReaT: Convolutional-Auxiliary Efficient Graph Reasoning Transformer for Dense Image Predictions. International Journal of Computer Vision, 2023.
- Yi Lin, Dong Zhang, Xiao Fang, Yufan Chen, Kwang-Ting Cheng, Hao Chen. Rethinking Boundary Detection in Deep Learning Models for Medical Image Segmentation. International Conference on Information Processing in Medical Imaging, 2023.
- Huimin Wu, Xiaomeng Li, Kwang-Ting Cheng. Exploring feature representation learning for semi-supervised medical image segmentation. IEEE Transactions on Neural Networks and Learning Systems, 2023.
- Xijie Huang, Jeffry Wicaksana, Shichao Li, Kwang-Ting Cheng. Automated vision-based wellness analysis for elderly care centers. AAAI Workshop: Health Intelligence, 2022.