Co-Design Digital Accelerators
Mixed-Bit Sparse CNN Accelerator
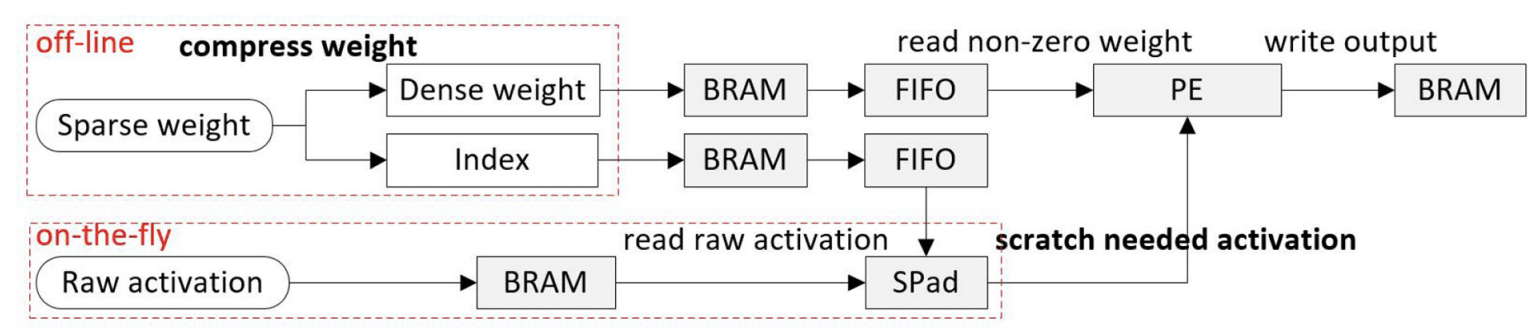
Regarding to pruning, unstructured pruning improves compression ratio, but the irregularity affects
the performance of parallel computing. A sparse model not only requires decoding, but also causes
weight loading imbalance and activation reading difficulty. The weight compression and input activation
scratch are the two most import processes. Since scratching activations is done on-the-fly which require
lots of hardware resources, the key point of scratch pad is decreasing hardware resources. Thus, an efficient
data fetch method is important for an accelerator that supports sparse CNN. Regarding to quantization, compared
with 32-bit float point, fixed point can reduce hardware resources, such as DSP, LUTs, and BRAM. Generally speaking,
mixed-bit quantization requires less computation resources than a single bit width while maintaining network
accuracy. However, hardware architectures may become extremely complex to support mixed-bit computation, as data flow,
memory structure, and PE need to be reconfigured online to support multiple bit-width computations. Thus, it is
important for an architecture to support multiple bit-width computations.
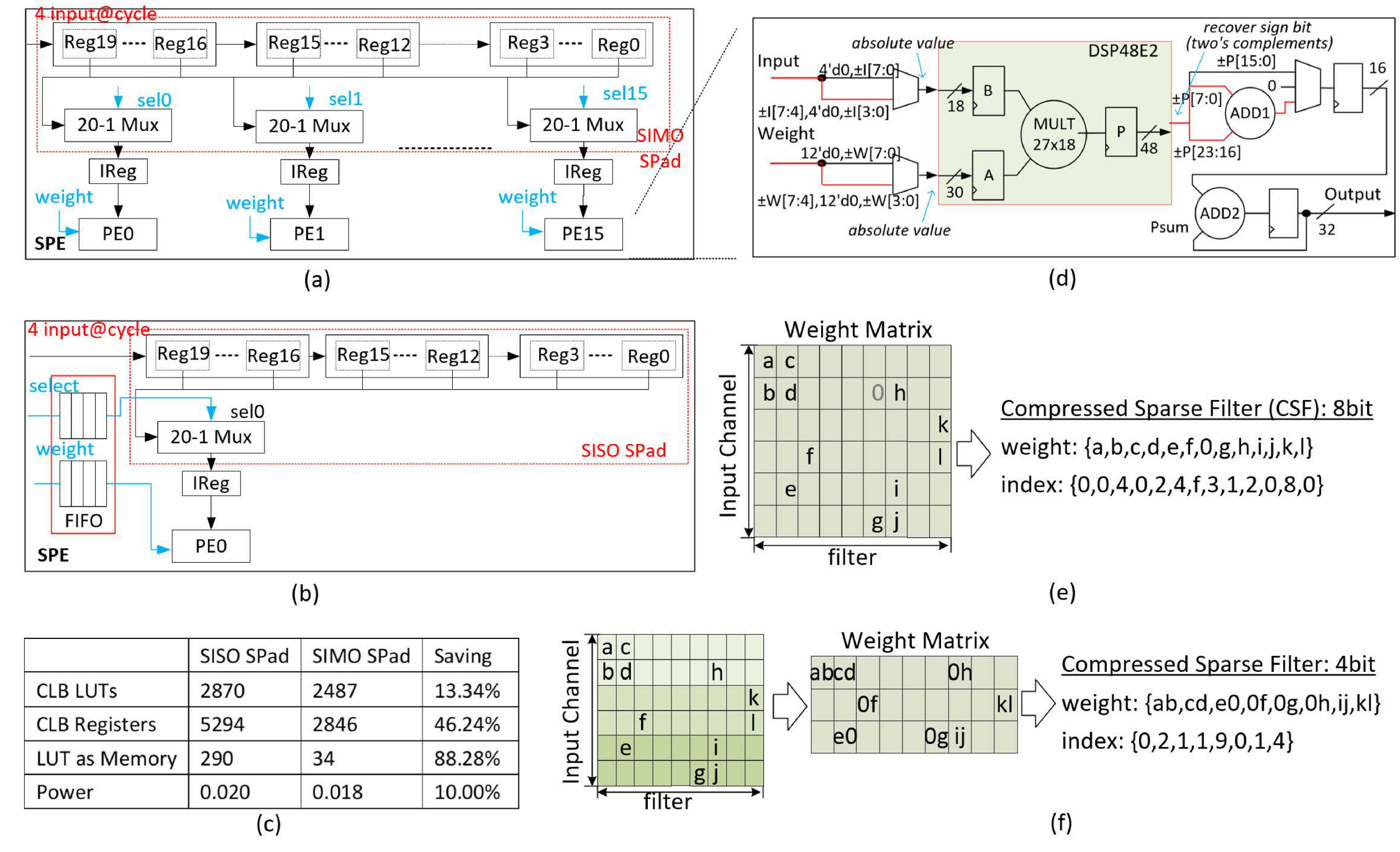
Unstructured pruning requires a customized hardware accelerator,
and the main issues for an accelerator are how to scratch
needed input activations and compress weights efficiently.
(b) shows a traditional architecture for weight sparsity.
Each PE is independent and calculates asynchronously,
so it has local SPad to fetch activations and FIFOs
to pre-store the weights and selection signals. We named this
traditional data fetch method as single input single output
scratch pad (SISO SPad). In this brief, a new fetch method,
SIMO SPad, is proposed to reduce hardware overhead, as
shown in (a). While sharing SPad reduces hardware consumption,
the FIFOs for pre-store weights and selection signals
are removed, further saving hardware resources. Compared to
SISO SPad method, SIMO SPad method can reduce hardware
significantly, saving 13.34% CLB LUTs, 46.24% CLB
Registers, and reducing 10% power. Mixed-bit CNNs are better than one-bit
in terms of accuracy, model size, memory access and performance. However,
few accelerators can support both mixed-bit width and sparsity
because it is a challenge to implement 8-bit architecture to
effectively support 4-bit sparsity. We design a DSP-base PE
which can be configured to implement one signed INT-8
or two signed INT-4 convolution operations as shown in (d).
Since lower-bit multiplication would impact upper-bit multiplication when a
DSP conducts two signed multiplications, this work introduces
a method of using absolute values for multiplication
and then recovering sign bit for accumulate operation.
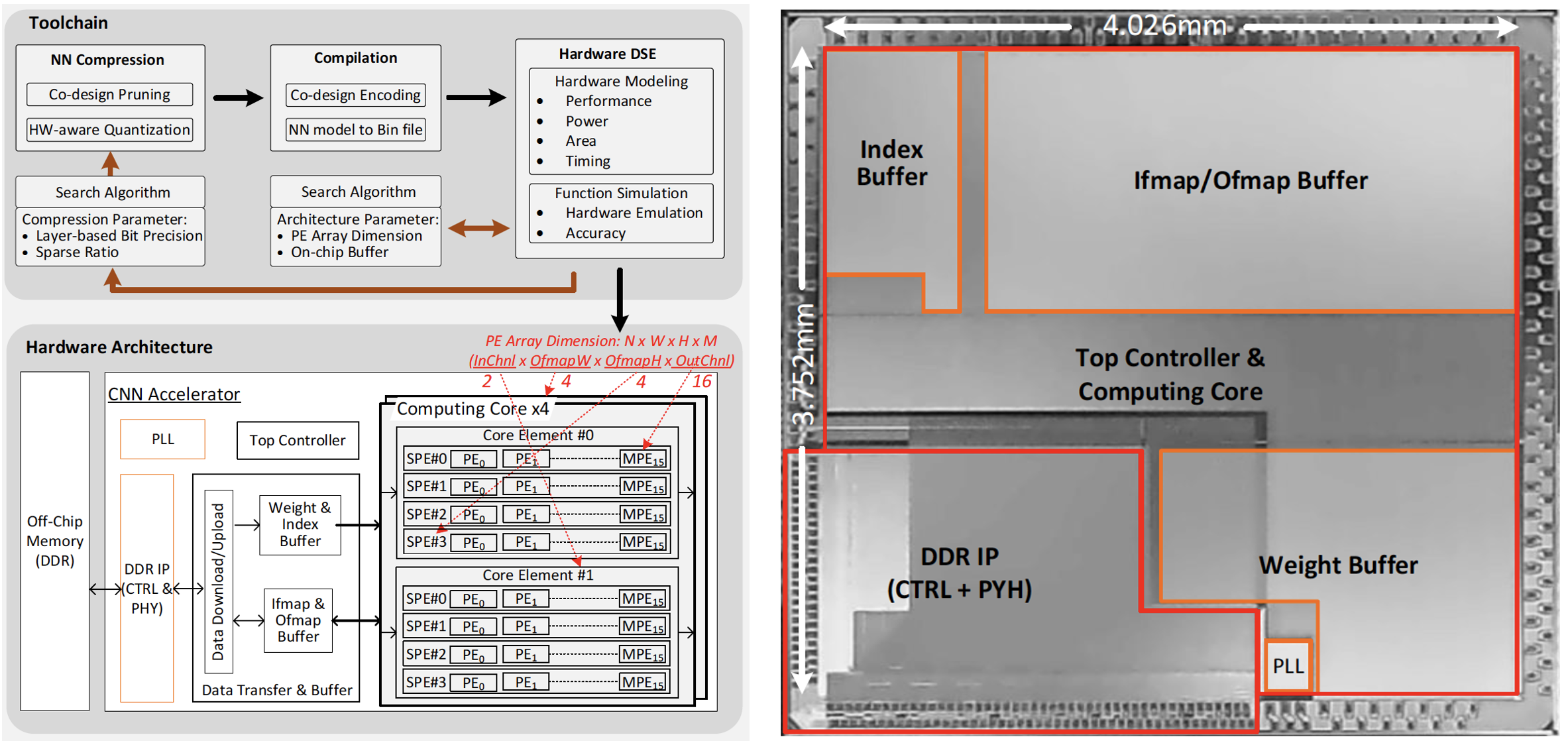
We further proposed a compression-hardware co-design approach, which includes the developed toolchain and
implemented accelerator architecture. The toolchain comprises three modules: NN Compression, Compilation,
and Hardware DSE. The NN Compression module performs co-design pruning and hardware(HW)-aware quantization.
The Compilation module handles co-design encoding and converting NN model to binary (Bin) files, which can
be executed by the implemented accelerator as well as the Function Simulation of the Hardware DSE module.
The Hardware DSE module, which comprises Hardware Modeling and Function Simulation, evaluates the PPA and
NN accuracy simultaneously for given hardware hyper-parameters and NN compression schemes in the design space.
The Hardware DSE can adopt search strategy such as greedy algorithm and tabu algorithm, to identify the optimal
architecture hyper-parameters, such as PE array dimension, that provides the best PPA performance. We proposed
a 4-dimentional CNN accelerator architecture hierarchically organized by N core elements, W computing cores,
H Sparse PEs (SPEs) and M PEs, where N, W, H and M map to input channel number, output feature map width,
output feature map height and output channel number, respectively. The accelerator calculates a W x H x M block
of output feature maps in parallel. We take an target accelerator of 512 PEs as an example and search the hyper-parameter (N, W, H, M).
Reference
- Xianghong Hu, Xuejiao Liu, Yu Liu, Haowei Zhang, Xijie Huang, Xihao Guan, Luhong Liang, Chi Ying Tsui, Xiaoming Xiong, Kwang-Ting Cheng. "A Tiny Accelerator for Mixed-Bit Sparse CNN Based on Efficient Fetch Method of SIMO SPad." In IEEE Transactions On Circuits And Systems II: Express Briefs, 2022.