CAE-GReaT: Convolutional-Auxiliary Efficient Graph Reasoning Transformer for Dense Image Predictions

Convolutional Neural Networks (CNNs) and Vision Transformer (ViT) are two primary frameworks for current semantic image recognition tasks in the community of computer vision. The general consensus is that both CNNs and ViT have their latent strengths and weaknesses, e.g., CNNs are good at extracting local features but difficult to aggregate long-range feature dependencies, while ViT is good at aggregating long-range feature dependencies but poorly represents in local features.
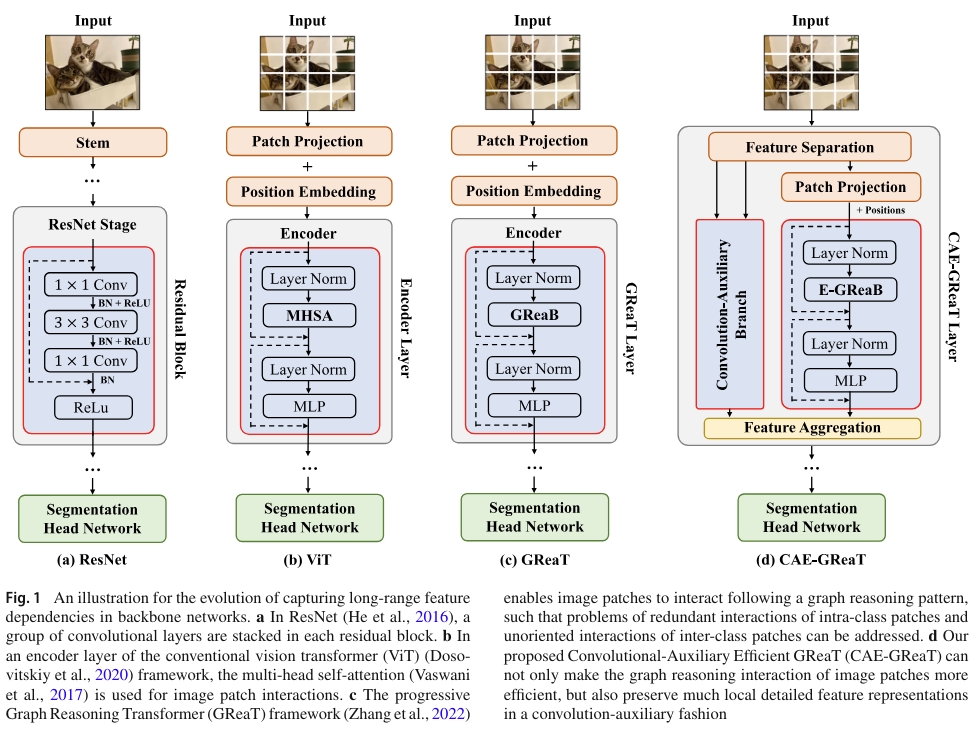
We propose an auxiliary and integrated network architecture, named Convolutional-Auxiliary Efficient Graph Reasoning Transformer (CAE-GReaT), which joints strengths of both CNNs and ViT into a uniform framework. CAE-GReaT stands on the shoulders of the advanced graph reasoning transformer and employs an internal auxiliary convolutional branch to enrich the local feature representations. Besides, to reduce the computational costs in graph reasoning, we also propose an efficient information diffusion strategy. Compared to the existing ViT models, CAE-GReaT not only has the advantage of a purposeful interaction pattern (via the graph reasoning branch), but also can capture fine-grained heterogeneous feature representations (via the auxiliary convolutional branch).
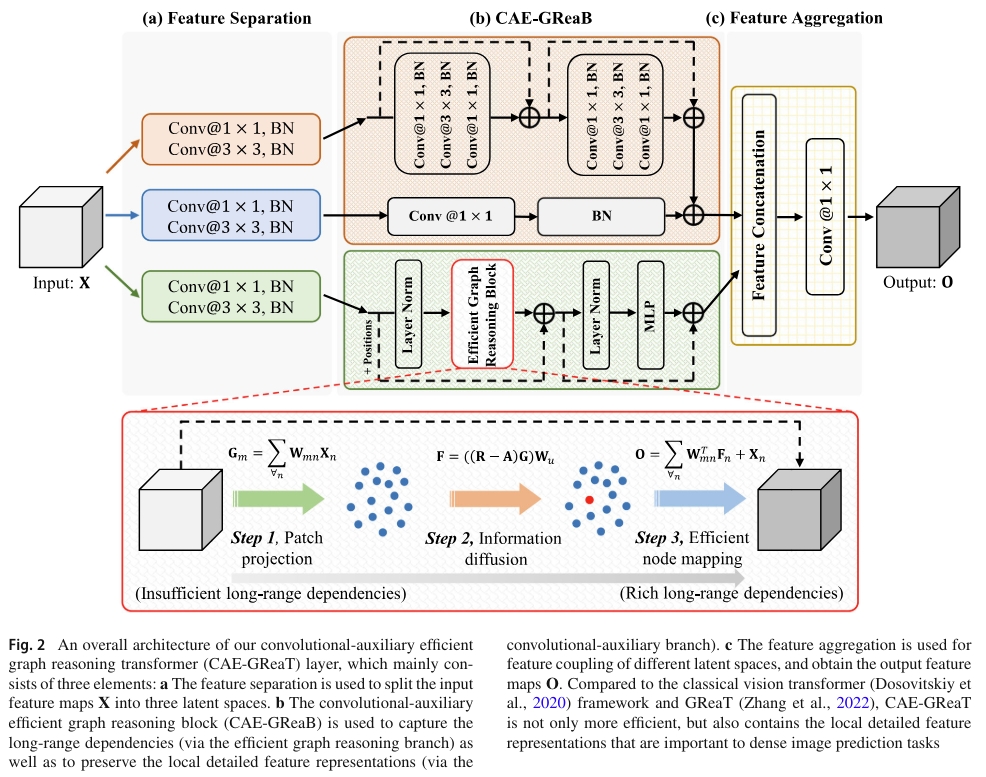
The main contributions of this paper are summed up as: (1) a uniform CAE-GReaT framework for DIP tasks is proposed to address ViT’s inherent problems by capturing the local feature representations; (2) we achieve the consistent performance gains on several dense image prediction tasks with the state-of-the-art ViT baselines with slightly computational costs.
Extensive experiments are implemented on three challenging dense image prediction tasks, i.e., semantic segmentation, instance segmentation, and panoptic segmentation. Results demonstrate that CAE-GReaT can achieve consistent performance gains on the state-of-the-art baselines with a slightly computational cost.